LLMOps – Large Language Model data plumbing in real-world applications
July 24, 2025 | DiffusionData
Overcoming the challenges of running AI in the enterprise
We’ve entered an era where deploying a single LLM is just the beginning. The real challenge – and opportunity – lies in orchestrating multiple models, data streams, and human expertise into seamless, production-ready systems.
When building any of the following functions have you considered these issues?
Dynamic LLM Routing has become essential as teams realize different models excel at different tasks. You might need to route creative writing to one model, technical analysis to another, and cost-sensitive queries to a lighter alternative.
A/B Testing in Production Teams need to seamlessly validate different LLMs with live users, comparing not just accuracy but latency, cost, and user satisfaction. This requires sophisticated traffic splitting and metric collection without disrupting the user experience.
Multi-Model Collaboration opens new possibilities but adds complexity. Imagine multiple LLMs discussing problems, peer-reviewing outputs, or building on each other’s responses. This requires intensive coordination of model interactions and output synthesis.
Human-AI Hybrid Workflows acknowledge that LLMs aren’t perfect. Smart systems route conversations between LLMs and human experts based on confidence scores, topic sensitivity, or business rules. This handoff must be seamless and maintain conversation context.
LLM Redundancy ensures your AI features don’t become single points of failure. High availability requires load balancing across multiple models, automatic failover, and graceful degradation when services are unavailable.
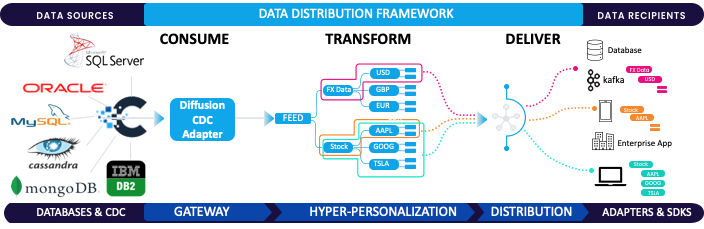
Broadcast & Fan-out patterns emerge when LLM outputs need to reach multiple consumers instantly – updating databases, triggering workflows, notifying users, or feeding into analytics pipelines. This requires flexible routing and effective scaling.
Multiple LLMs means Complex MCP Configurations. Connecting LLMs to diverse data sources via Model Context Protocol (MCP) servers is complex. Each server and model might need different data access patterns, hosting, and integration points.
We built a platform that can help you solve these issues. Watch the technical explainer here.
DiffusionData – Building for the Future
The production challenges of LLM deployment – dynamic routing, redundancy, complex integrations – require sophisticated infrastructure that most teams shouldn’t have to build from scratch. DiffusionData’s Diffusion Server provides a proven foundation, already trusted by companies worldwide for mission-critical real-time data distribution.
At its core, Diffusion leverages Websockets for low-latency, persistent connections that enable seamless two-way communication between LLMs, users, and systems. This makes Human-AI workflows feel instantaneous while supporting complex broadcast and fan-out patterns.
Whether deployed on-premise, in the cloud, or hybrid, Diffusion server ensures your LLM infrastructure remains available and responsive globally. With Diffusion handling the data plumbing, teams can focus on building innovative AI applications rather than wrestling with distributed systems challenges.
You can start your free trial of Diffusion Cloud today: Sign up for free
Further reading
BLOG
The Game-Changer: Change Data Capture (CDC)
March 17, 2025
Read More about The Game-Changer: Change Data Capture (CDC)/span>

BLOG
How to Cut Cloud Costs for Real-Time Data Streaming
July 10, 2025
Read More about How to Cut Cloud Costs for Real-Time Data Streaming/span>

BLOG
Streaming and Data Privacy: Are you Ready for AI + GDPR?
July 29, 2025
Read More about Streaming and Data Privacy: Are you Ready for AI + GDPR?/span>




