Integration with Diffusion: The Gateway Framework
May 30, 2022 | DiffusionData
Release 6.8 of the Diffusion Intelligent Data Platform for real-time applications, supports a powerful new feature called the ‘Gateway Framework’.
What is the Gateway Framework?
For many years Diffusion has been a leading-edge technology product concentrating on the fast and efficient caching and delivery of data to diverse clients, such as web, mobile, IoT, etc. In more recent years it has also been extended to provide no-code server-side wrangling (or transformation) of data. It also provides powerful feature-rich SDKs in many programming languages for the consumption and updating of such data. However, until now, it has been necessary to write ‘control client’ applications using the Diffusion Client SDKs to integrate with Diffusion, but that involved a significant understanding of Diffusion concepts and the Diffusion Client SDKs. But often our customers simply want to integrate their other systems and applications with Diffusion without having to learn the Client APIs or the Diffusion concepts. They simply want to feed data into a Diffusion server so that it can be distributed efficiently to consuming clients, or conversely, they may want to subscribe to data from Diffusion and feed it to external systems with the minimum development effort. In addition, users want to be able to manage their Diffusion applications from some external mechanism.
The Gateway Framework removes the need for any significant Diffusion knowledge and provides a ‘low code’ solution to integration, where the application writer only needs to concentrate on the interactions with the external systems. In addition, the Gateway Framework is fully integrated with the Diffusion management console, allowing applications to be managed and monitored from the console. This includes the ability to dynamically change the configuration, and thus the functionality of the application directly from the console.
The Gateway Framework hides the normal Diffusion client processing, such as making and maintaining a connection to Diffusion, creating, updating, and removing Diffusion topics, subscribing to Diffusion topics, and so on. This allows the Diffusion user to concentrate solely on the coding needed to access external systems.
The Gateway Framework can be used by Diffusion customers to write Gateway applications specific to their business requirements. Push Technology will use the Diffusion Framework to provide standard ‘adapters’. And third party developers can use the Gateway Framework to develop applications to be used with Diffusion. This all provides an integrated environment for running and managing applications that interact with Diffusion servers.
The Gateway Framework is a separately released product, built on top of the Diffusion Java Client and supported by release 6.8 of Diffusion onwards. It has a Java API which allows users to implement applications by just implementing a few supplied interfaces. It is released initially as a beta version to enlist user feedback and will be followed by a fully supported version in the very near future.
Gateway Framework Concepts
The diagram below illustrates some of the basic concepts related to the Gateway Framework.
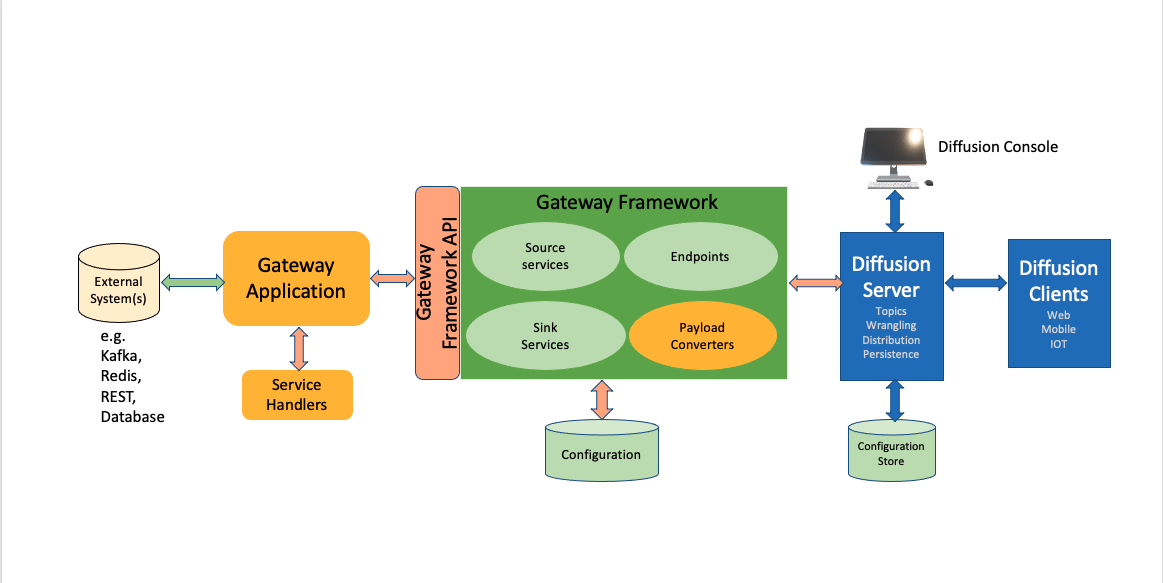
Gateway Users
There are two main user roles associated with the Gateway Framework :
- The Application Writer develops a Gateway Application using the Gateway Framework API.
- The Application User, configures the application to perform the tasks required by providing some configuration, either as a file or using the Diffusion Management Console. The user may also manage and monitor the application and its services using the Console.
Gateway Application
A Gateway Application is a Java class, written by an application writer, which provides the functionality necessary to access one or more backend systems. An application declares support for one or more service types and a service handler class must be provided for each service type that the application provides.
Service Types
A service type defines what a service does dependent upon configured parameters to the service. For example, a service type could stream updates from a Kafka topic to Diffusion and the parameters would indicate the location and name of the Kafka topic and the name of the Diffusion topic to publish to. The service handler makes the link to the Kafka topic and publishes updates to the Diffusion topic.
A service type can be a source service type or a sink service type. A source service consumes data from an external data source and publishes it to Diffusion, whereas a sink service consumes data from a Diffusion topic and publishes it to a back-end system.
Source service types can be streaming or polling. A streaming service is notified of updates to data and publishes to Diffusion as updates arrive. A polling service periodically polls an external data source and publishes updates to Diffusion.
Services
The Gateway Framework configuration for the application can specify the services required, indicating their service types. There can be any number of services defined for a single service type, all with different parameters.
Configuration
A Gateway Application’s runtime behavior is defined by its configuration. The configuration is a file specifying general application details and defining the services required. Each service must specify a service type that is declared by the application.
The configuration is specified as a file in JSON format. The application can be started up with a local configuration file. When an application connects to the framework a connection is made to the Diffusion server. The configuration may then be viewed and even updated using the Diffusion console. The configuration file is saved on the Diffusion server and if the application is restarted without a local configuration file, the configuration is retrieved from the server. This means that an application can start up initially with no configuration at all and all aspects (services, etc.) can then be defined using the console. The configuration that is saved at the server can be removed using the console to remove any record of an application. Once the configuration is saved at the server the console can view available applications even if they are not connected to the server.
Endpoints
A further option available to the application writer is the definition of endpoint types. An endpoint is a unit of configuration which unlike a service provides no functionality. Its purpose is to provide a common configuration that can be used across more than one service. For example, if there are several services that all access the same back-end system then it is easier to define the back-end connection details in one place than separately in every service. It also allows the application to manage connections to endpoints better as it can make and drop connections as they are required by the services that are running.
An application may optionally define endpoint types that it supports which allows the application user to define endpoints of those types and use them in different services.
Payload Convertors
Application writers will need to convert the data formats used by diverse back-end systems into the data format expected by Diffusion (typically JSON held in CBOR binary format) and vice versa. This is where payload convertors are used. A payload convertor is a named Java class that can be used by services to automatically convert the data as it comes into the framework or is sent out from the framework. As well as simply reformatting the data a payload convertor can perform any reformatting or sanitizing of data as required. An application writer can write payload convertors to do such conversions as necessary and then an application user can name the payload convertor to use when configuring services.
A payload convertor may be inbound (for converting external data to Diffusion format) or outbound (for converting Diffusion data to external format). Inbound convertors are used for streaming and polling source services and outbound convertors are used for sink services.
A number of standard convertors are provided with the framework which can be used without having to write one specifically. For example, there are standard inbound ones that can take JSON strings, CSV (Comma Separated Values), or Avro (Kafka) formats.
Gateway Application Identity
When an application writer develops a Gateway application they must provide a unique Gateway type that differentiates the application from other Gateway applications. A user wishing to run the application must provide an application identity, which again may be anything, and is used along with the application type to uniquely identify an application instance attached to a Diffusion server (or cluster).
The identity is linked to the configuration for the application instance and therefore an instance of the application started with the same identity as used previously can restore the saved configuration from the server where it is persisted from the first time the identity is used, and every time the configuration associated with the identity is updated.
Writing a Gateway Application
To get started, download the Gateway Framework bundle from the Push Technology website. The bundle contains the Gateway Framework jar, the Javadoc for the API, and a user guide.
It is relatively simple to write a Gateway Application. There is no need for any deep knowledge of Diffusion as the handling of Diffusion session connections, the creation, updating, and removal of topics and other Diffusion specific details are all dealt with by the framework. Of course, the application can be as complex as you want and can provide many different service types and configuration options. But to write a simple application that provides a single service type that consumes from a data source and publishes to a Diffusion topic is very simple.
In a nutshell, the application writer needs to :
- Decide upon the service types to provide.
What will the service do? Is it to stream updates to Diffusion, be polled for updates, or act as a sink and consume updates from Diffusion? - Decide the configuration parameters that a service type needs to implement different instances of it.
These are the parameters that the application user will pass when configuring a service to define what is actually required from the service. - Write a class that implements the
GatewayApplicationinterface provided in the API.
This will implement methods that the framework will call to obtain the service (and endpoint) types and create services (instances of the service type).
The application can also provide a schema for the application-specific parameters it requires, thus allowing the framework to validate them. - Write service handlers classes for each service type supported.
The handler will implement the API interfaceStreamingSourceHandler,PollingSourceHandlerorSinkHandler, depending on what mode the service type is.
Source handlers simply use apublishmethod to send updates to Diffusion, a polling source handler has apollmethod that is called when it is required to publish. Sink handlers have anupdatemethod that is called whenever a Diffusion topic they are consuming from is updated. - Write payload convertors as necessary.
If the standard issued payload convertors are not suitable then payload convertors may be required to transform the data from external to Diffusion format or vice versa. These implement a very simple interface.
Using a Gateway Application
A Diffusion user can write their own framework applications, or use those provided by Push Technology (Kafka, CDC, and a new REST adapter). The application, when deployed with suitable Diffusion connection details, can then be configured, managed, and monitored using the Diffusion Management Console.
There is the option to start the application with its initial configuration, or just start it ’empty’ and allow full configuration from the Console. The configuration is saved at the server so when the application is restarted it can load the previous configuration from the server. All changes to the configuration, done via the Console, are saved to the server.
Each application will have its own configuration requirements. The user guide provides information on how to configure the application and Diffusion to get the maximum performance from the application.
Future Developments
The first release of the Gateway Framework is a beta release, allowing users to try it out and provide feedback. Planned future additions to the functionality include :
- Resilience
Allowing multiple instances of applications to provide failover capability. - Management API
To allow the framework to be managed programmatically, rather than from the Diffusion Console. - More Data Wrangling
Additional out-of-the-box payload convertors.
Special transformation service type, acting as a sink and a source at the same time. - More Diffusion Options
Exploiting more Diffusion capabilities, such as topic locking, topic views, etc.
Summary
The release of the Gateway Framework provides an exciting new stage in the development of the Diffusion product, allowing easy integration of Diffusion with external systems of diverse types. This supports our continuing effort to make Diffusion easier to use. This allows customers to very quickly implement low code Diffusion based solutions. The framework will significantly cut development and maintenance costs for customers and opens up the possibility of a new community of Diffusion application developers.


