100 million updates per second – Landmark Diffusion cluster performance
July 2, 2024 | Adam Turnbull
Introduction
We recently wrote about how good Diffusion is at scaling out to large numbers of subscribers. But what if you’re more interested in the raw performance rather than catering for tens of thousands of subscribers? It turns out that Diffusion can do that pretty well too.
What sort of use case might this be? It’s common in market data distribution where a relatively small set of subscribers want all the data you have – or a good sized subset of it – as quickly as possible.
Scenario
To show what Diffusion can do, we set up a test with the following parameters:
100,000 topics, of 200 bytes each
10,000 updates/sec across the topic tree, from a single publisher
10,000 subscribers, each one subscribing to the entire topic tree
This works out to 100,000,000 updates/sec with an outgoing bandwidth of around 149 Gbit/sec, plus any application and TCP enveloping.
The goal is to get Diffusion to deliver all updates to every subscriber with a latency of under 10ms at the 99th percentile. All updates need to be in order, and no updates dropped.
Tuning
The key to getting data from A to B as quickly as possible is to make the path that it has to travel as straight as possible; don’t do anything unnecessary with the data as it moves through the system. Diffusion gives us a lot of flexibility with what we can tweak, so we turn off the following features that we won’t need:
Conflation: By default, if a backlog of messages builds up, Diffusion is permitted to merge updates to a single topic to deliver the latest value only. While this helps slow consumers, market data is often sensitive to “missing” updates, so we turn this feature off.
Compression: With small messages, the benefit of compression to reduce data sizes is relatively small compared to the CPU overhead needed for it. Our test environment has sufficient bandwidth capacity and any small improvements here will not be a significant benefit.
Deltas: For any given topic, Diffusion can choose to only transmit the difference between one value and the next. In many cases it gives better bandwidth savings than traditional compression, but there is a CPU cost to the delta calculation. As previously stated, we have enough network bandwidth that we don’t need to use deltas.
Caching: Diffusion will act as a “last value cache”, retaining the last value for any topic. Very often, market data consumers are building their own model of the market from the events that they receive from their subscriptions so there is no requirement for state on the server.
Environment and testing
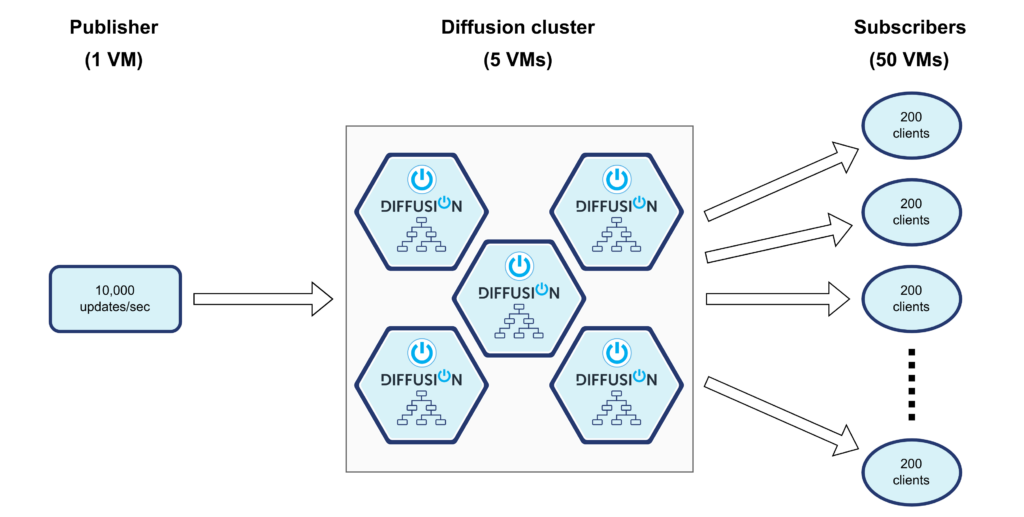
We chose to run this test in AWS with the following VMs:
| Component | VM type | # CPUs | # VMs |
|---|---|---|---|
| Publisher | c6in.2xlarge | 8 | 1 |
| Diffusion server | c6in.8xlarge | 32 | 5 |
| Subscriber | c6in.2xlarge | 8 | 50 |
The publisher and subscriber applications are an internal DiffusionData tool, “Autobench” that we use for benchmarking. It’s good at publishing data quickly (using standard Diffusion Java APIs) and will record the latency for each message from the point of publication to when it is received by the subscriber.
With 50 VMs, we have 200 clients per machine, each with 10,000 subscriptions. In the real world you wouldn’t have this many – each client would probably have their own dedicated machine, so the number of subscriber VMs is not really important to the test as long as we’re not overloading them.
Diffusion is set up as a cluster of 5 servers, running Diffusion 6.11:
Summary
This configuration proved to be capable of handling the throughput required, with 100 million messages delivered every second, in order and without loss, at a latency of 5ms at the 99th percentile.
While Diffusion is often used to distribute stateful data to a very large number of subscribers, and has some great features for reducing down and managing network bandwidth, it can equally be used for moving large volumes of data at high speed. The key to this is choosing which features you need, and which you don’t – something that Diffusion gives you control over.
Diffusion’s clustering has reached a new landmark in pub/sub cache server performance with these results.


